程序人生
AI绘图
线性表
CLIP
File的创建功能
学生我那工业作业
Linux虚拟主机
队列
SpringBoot项目的创建
halcon
AMQP
生信服务
云管理
mfc
高级IO
制造业
图像增强
第三方库
高等数值计算方法
前向和反向传播
交叉熵
2024/4/13 16:39:23
【AI面试】损失函数(Loss),定义、考虑因素,和怎么来的
神经网络学习的方式,就是不断的试错。知道了错误,然后沿着错误的反方向(梯度方向)不断的优化,就能够不断的缩小与真实世界的差异。
此时,如何评价正确答案与错误答案,错误的有多么的离谱,就需要一个评价指标。这时候,损失和损失函数就运用而生。
开始之前,我们先做…
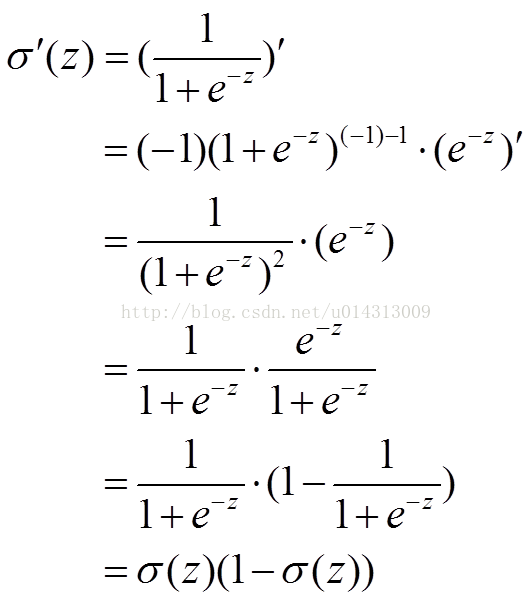
交叉熵的解决代价函数为二次函数导致学习慢问题(S型激活函数)
1.从方差代价函数说起 代价函数经常用方差代价函数(即采用均方误差MSE),比如对于一个神经元(单输入单输出,sigmoid函数),定义其代价函数为: 其中y是我们期望的输出,a为神经元的实际输…

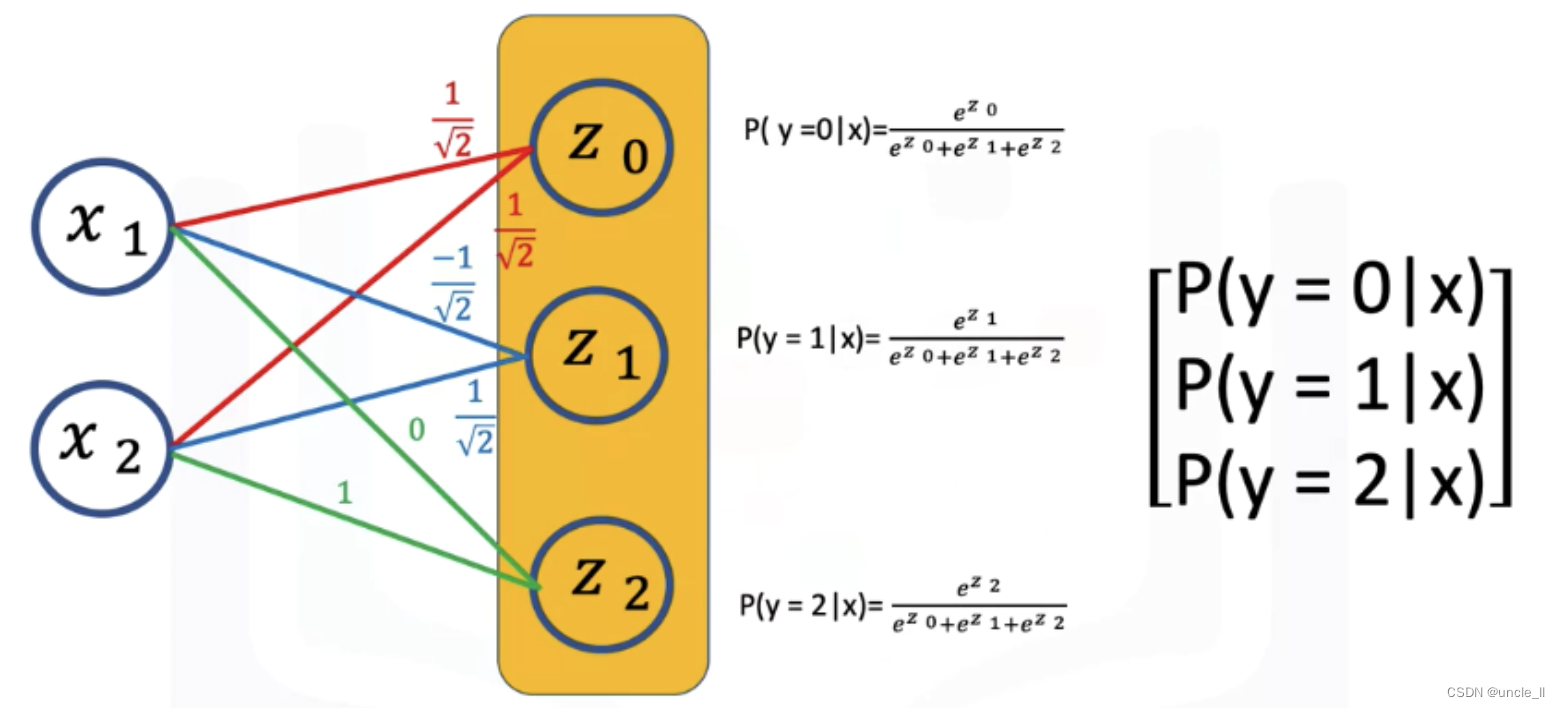
交叉熵和softmax
交叉熵cross-entropy loss 最大化似然函数,最小化负的似然对数函数
最终的交叉熵损失函数,最小化该loss: nn.BCELoss
def criterion(yhat, y):out -1 * torch.mean(y*torch.log(yhat) (1-y) * torch.log(1-yhat))return outsoftmax

一文说清楚你头疼不已的熵们:信息熵、联合熵、条件熵、互信息、交叉熵、相对熵(KL散度)
文章目录1. 信息熵2. 联合熵3. 条件熵4. 互信息5. 交叉熵6. 相对熵(KL散度)7. 总结说起熵,相信看本文的你一定听过这个概念,我们以前高中的时候在化学里学过,我们有一种大致的概念就是:熵是描述系统混乱程度…
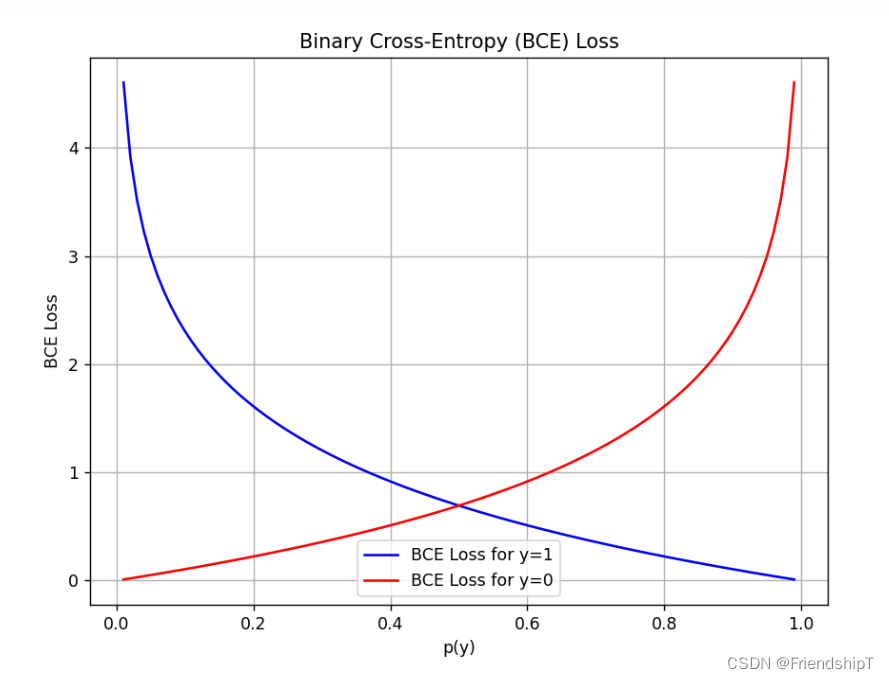
损失函数:BCE Loss(二元交叉熵损失函数)、Dice Loss(Dice相似系数损失函数)
损失函数:BCE Loss(二元交叉熵损失函数)、Dice Loss(Dice相似系数损失函数) 前言相关介绍BCE Loss(二元交叉熵损失函数)代码实例直接计算函数计算 Dice Loss(Dice相似系数损失函数&a…

PyTorch----Softmax函数与交叉熵函数
二分类问题和多分类问题
二分类问题: 分类任务中有两个类别。比如前面感知机识别香蕉还是苹果,一般会训练一个分类器,输入一幅图像,输出该图像是苹果的概率为p,对p进行四舍五入,输出结果为0或者1ÿ…

一篇文章彻底搞懂熵、信息熵、KL散度、交叉熵、Softmax和交叉熵损失函数
文章目录 一、熵和信息熵1.1 概念1.2 信息熵公式 二、KL散度和交叉熵2.1 KL散度(相对熵)2.2 交叉熵 三、Softmax和交叉熵损失函数3.1 Softmax3.2 交叉熵损失函数 一、熵和信息熵
1.1 概念 1. 熵是一个物理学概念,它表示一个系统的不确定性程度,或者说是…

深度学习(一):交叉熵损失函数,信息量,熵,KL散度
交叉熵损失函数「Cross Entropy Loss」,我们第一印象就是它如下的公式: 大多数情况下都是直接拿来使用就好,但是它是怎么来的?为什么它能表征真实样本标签和预测概率之间的差值?交叉熵函数是否有其它变种? …


损失函数(MSE和交叉熵)
全连接层解决MNIST:只是一层全连接层解决MNIST数据集 神经网络的传播:讲解了权重更新的过程 这个系列的文章都是为了总结我目前学习的积累。 损失函数
在我文章的网络中,我利用MSE(mean-square error,均方误差&…

F.binary_cross_entropy、nn.BCELoss、nn.BCEWithLogitsLoss与F.kl_div函数详细解读
提示:有关loss损失函数详细解读,并附源码!!! 文章目录 前言一、F.binary_cross_entropy()函数解读1.函数表达2.函数运用 二、nn.BCELoss()函数解读1.函数表达2.函数运用 三、nn.BCEWithLogitsLoss()函数解读1.函数表达…
与信息熵相关的概念梳理(条件熵/互信息/相对熵/交叉熵)
香农信息量
信息量表示不确定性的大小。 信息量的单位是比特(bit)。 香农信息量log1p−logp(以2为底)香农信息量\log\frac{1}{p}-\log p\quad(以2为底)香农信息量logp1−logp(以2为底)
上式中,p越小,则不确定性越大&#…
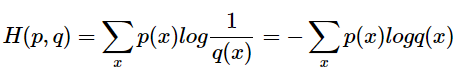
信息熵、相对熵与交叉熵
目录1. 信息熵2. 相对熵3. 交叉熵4. 交叉熵与softmax1. 信息熵 熵是一个信息论中的概念,表示随机变量不确定的度量,是对所有可能发生的事件产生的信息量的期望。信息熵公式如下: H(p)−∑i1np(xi)logp(xi)H(p)-\sum_{i1}^{n}{p(x_i)logp(x_i)…